
We had several of our Computer Science students participate in the Student Research Symposium that took place March 8th and 9th. Four of our students gave a research presentation in front of a judging panel. We are excited that our computer science students are getting involved in campus wide activities and commend each one of them for a job well done. Their research abstracts are below.
The database and interaction of VDM project
Heqiao Liu, Computer Science
Robert Edwards, Computer Science
 The Viral Dark Matter project (VDM) aims to explore those genes in viruses which we do not have much knowledge of. The project produces huge amounts of experimental data, requiring a database, and users need the ability to upload, query, request, and visualize the data. The database and interaction of VDM project contains four layers: database, module, controller and web-based user interface.
The Viral Dark Matter project (VDM) aims to explore those genes in viruses which we do not have much knowledge of. The project produces huge amounts of experimental data, requiring a database, and users need the ability to upload, query, request, and visualize the data. The database and interaction of VDM project contains four layers: database, module, controller and web-based user interface.
The project uses mySQL, a relational database, and associates experimental results, background, and relevant data in the fields. The database was built using a model-view-controller (MVC) approach to database and web design.
Modules written in PHP, provide a convenient way to insert and select data from the database. Each module is responsible for one of tables in the database. The modules optimize manipulations within the database, so for example commonly used database requests result in simple function calls instead of duplicate complex queries. The modules provide easy, stable interfaces to access the database.
Controllers are built at the layer between modules and clients (e.g. a web-based user interface). They provide functions that return data objects due to different tasks. Each function in a controller may call one or more functions of modules; then a set of data is reformatted into JSON (JavaScript Object Notation).
The web-based user interface uses PHP, JavaScript and standard JavaScript libraries. It provides functions to upload data into the database, and visualize or export data. To keep the web-page stable, it is designed to load the minimum amount of data possible, and send dynamic request to get data through controllers and modules during actions. As a result, the pages response sensitively, even though there are huge amount of data in the database.
The four layers of the project are stably implemented. The next phase of the project revolves around developing an application programming interface (API) to allow programmatic access to the data.
Plugin architecture for creating algorithms for bioacoustic signal processing software
Christopher Marsh, Computer Science
Marie Roch, Computer Science
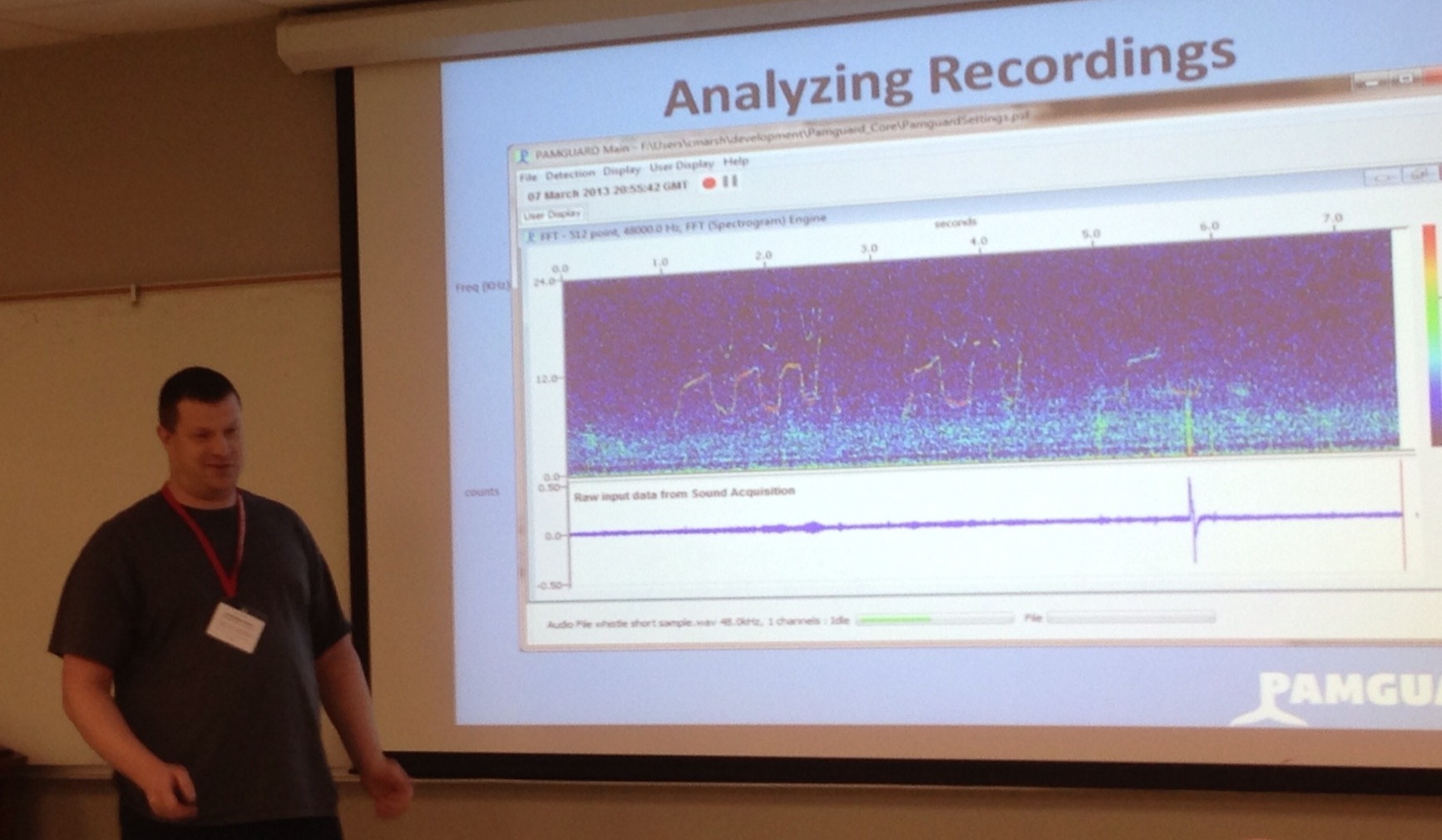 Animal bioacoustics, the study of sound produced and received by animals, is assisted by signal processing and classification algorithms that allow researchers to quickly analyze recordings that may be sparsely populated with interesting animal sounds. Several publicly available programs allow researchers to write and execute their own algorithms that automate the detection, classification, and localization of these sounds. However, it can be difficult to write algorithms for these programs. Development requires intimate knowledge of the host environment, development in other languages is not easily supported, and the algorithm must be redeveloped to run in other bioacoustics packages. Two of the most popular software packages used for marine mammal bioacoustics, Ishmael and PamGUARD, are written in programming languages that are not widely used by the bioacoustics community, adding to this challenge. An application programming interface (API) has been developed to resolve these issues by providing a plugin framework for creating algorithms for these programs. This API permits algorithms to be written once in a wide variety of languages and provides seamless integration into the aforementioned packages. We hope that this will promote the sharing and reuse of algorithm code between bioacoustics researchers.
Animal bioacoustics, the study of sound produced and received by animals, is assisted by signal processing and classification algorithms that allow researchers to quickly analyze recordings that may be sparsely populated with interesting animal sounds. Several publicly available programs allow researchers to write and execute their own algorithms that automate the detection, classification, and localization of these sounds. However, it can be difficult to write algorithms for these programs. Development requires intimate knowledge of the host environment, development in other languages is not easily supported, and the algorithm must be redeveloped to run in other bioacoustics packages. Two of the most popular software packages used for marine mammal bioacoustics, Ishmael and PamGUARD, are written in programming languages that are not widely used by the bioacoustics community, adding to this challenge. An application programming interface (API) has been developed to resolve these issues by providing a plugin framework for creating algorithms for these programs. This API permits algorithms to be written once in a wide variety of languages and provides seamless integration into the aforementioned packages. We hope that this will promote the sharing and reuse of algorithm code between bioacoustics researchers.
Determining Dolphin Species by their Echolocation Clicks: A Study of the Effects of Site Variability, Noise, and Recording Equipment Differences
Johanna Stinner-Sloan, Computer Science
Marie Roch, Computer Science
 There are already a few methods in existence for classifying odontocetes (“toothed whales”, including all dolphins and porpoises) based on the cepstral features of their echolocation clicks. The research that we have done is towards developing methods for removing ocean background noise from the clicks, better rejecting anthropogenic clutter in the form of sonar, and providing compensation for differences between recording equipment in order to reduce the error rates of the classification. Previous methods have utilized two-pass systems in order to first identify areas of clicks and later narrow down focus onto those specific areas to extract the click features without utilizing any form of noise removal. The method developed during the course of our research is a one-pass system that detects potential clicks based on their relative Teager Energy (the energy required to produce them). Sonar pings are located by observing the correlation between the times of possible clicks and removing those that appeared at regular intervals consistent with sonar systems. Unreliable clicks are further removed by checking for clipping, the length of the clicks, and the percentage of frequencies over a designated threshold. Noise is calculated as a moving average over areas of sufficiently low energy that are of distant from areas with dense echolocation activity. This research was done using recordings of Pacific White-Sided Dolphins and Risso’s Dolphins found off the coast of Southern California from autonomous seafloor moored instruments. Current results show that although the error rate still remains above that of our two pass baseline system, removing the ambient noise from the click features improves the classification results over a large number of semi-randomized tests.
There are already a few methods in existence for classifying odontocetes (“toothed whales”, including all dolphins and porpoises) based on the cepstral features of their echolocation clicks. The research that we have done is towards developing methods for removing ocean background noise from the clicks, better rejecting anthropogenic clutter in the form of sonar, and providing compensation for differences between recording equipment in order to reduce the error rates of the classification. Previous methods have utilized two-pass systems in order to first identify areas of clicks and later narrow down focus onto those specific areas to extract the click features without utilizing any form of noise removal. The method developed during the course of our research is a one-pass system that detects potential clicks based on their relative Teager Energy (the energy required to produce them). Sonar pings are located by observing the correlation between the times of possible clicks and removing those that appeared at regular intervals consistent with sonar systems. Unreliable clicks are further removed by checking for clipping, the length of the clicks, and the percentage of frequencies over a designated threshold. Noise is calculated as a moving average over areas of sufficiently low energy that are of distant from areas with dense echolocation activity. This research was done using recordings of Pacific White-Sided Dolphins and Risso’s Dolphins found off the coast of Southern California from autonomous seafloor moored instruments. Current results show that although the error rate still remains above that of our two pass baseline system, removing the ambient noise from the click features improves the classification results over a large number of semi-randomized tests.
A Method for Minimizing Computing Core Costs in Cloud Infrastructures that Host Location-Based Advertising Services
Vikram Ramanna, Computer Science
Christopher Paolini, Computational Science Research Center
Cloud computing provides services to a large number of remote users with diverse requirements, an increasingly popular paradigm for accessing computing resources over the Internet. A popular cloud-service model is Infrastructure as a Service (IaaS), exemplified by Amazon’s Elastic Computing Cloud (EC2). In this model, users are given access to virtual machines on which they can install and run arbitrary applications, including relational database systems and geographic information systems (GIS). Location-based services (LBS) for offering targeted, real-time advertising is an emerging retail practice wherein a mobile user receives offers for goods and services through a smart phone application. These advertisements can be targeted to individual potential customers by correlating a smart phone user’s interests to goods and services being offered within close proximity of the user. In this work, we examine the problem of establishing a Service Level Agreement (SLA) to determine the appropriate number of microprocessor cores required to constrain the query response time for a targeted advertisement to reach a mobile customer, within approachable distance to a Point of Sale (POS). We assume the optimum number of cores required to maintain a SLA is one which minimizes microprocessor core expenses, charged by infrastructure providers, while maximizing application service provider revenues derived from POS transaction fees. This problem is challenging because changes in the number of microprocessor cores assigned to database resources can result in changes in the time taken to transmit, receive, and interpret a targeted advertisement sent to a potential customer in motion. We develop a methodology to establish an equilibrium state between the utility gained from POS transaction revenues and costs incurred from purchasing microprocessor cores from infrastructure providers. We present different approaches based on an exponential, linear, and Huff method to model customer purchase decisions. From these models, the marginal cost and marginal revenue is calculated to determine the optimal number of microprocessor cores to purchase and assign to database resources.